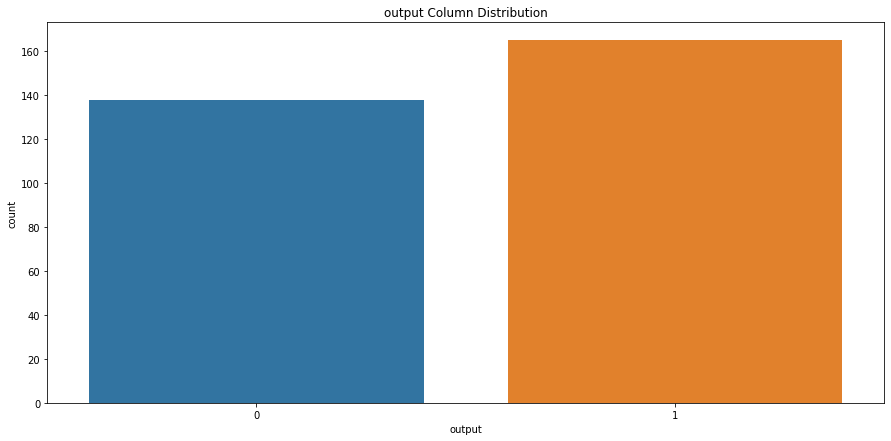
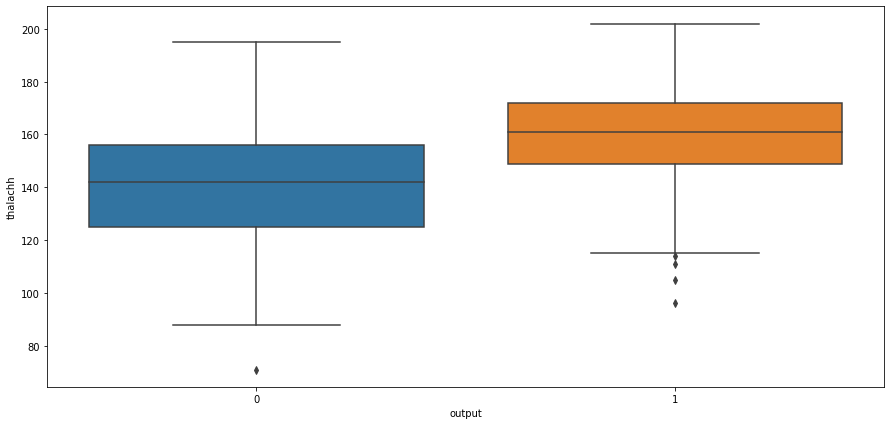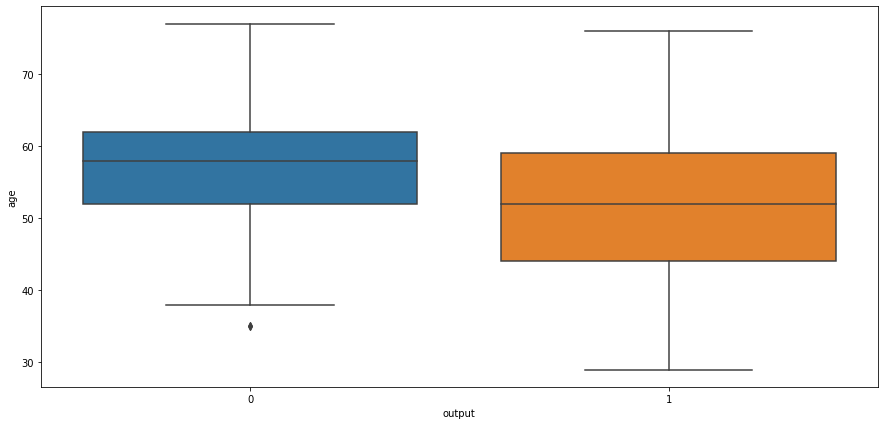# check output column class distributionsns.countplot(x='output', data=heart_df).set_title("output Column Distribution")
Text(0.5, 1.0, 'output Column Distribution')
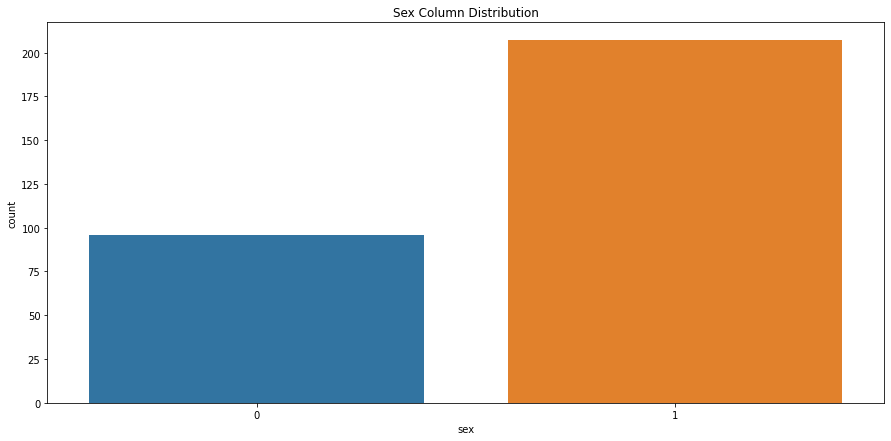
# check sex column class distributionsns.countplot(x='sex', data=heart_df).set_title("Sex Column Distribution")
Text(0.5, 1.0, 'Sex Column Distribution')
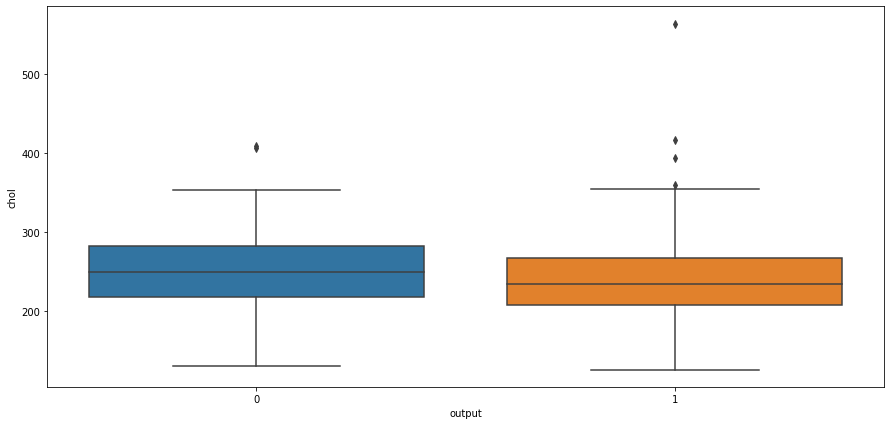
# box plot for output and cholestrol levelsns.boxplot(x="output",y="chol",data=heart_df)
<AxesSubplot:xlabel='output', ylabel='chol'>
# box plot for output and cholestrol levelsns.boxplot(x="output",y="thalachh",data=heart_df)
<AxesSubplot:xlabel='output', ylabel='thalachh'>
# box plot for output and cholestrol levelsns.boxplot(x="output",y="oldpeak",data=heart_df)
<AxesSubplot:xlabel='output', ylabel='oldpeak'>
# box plot for output and cholestrol levelsns.boxplot(x="output",y="age",data=heart_df)
<AxesSubplot:xlabel='output', ylabel='age'>
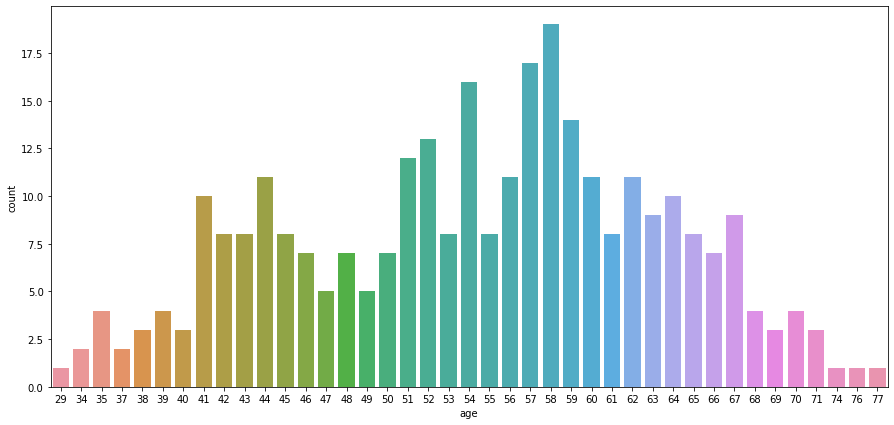
ax = sns.countplot(x='age', data=heart_df)
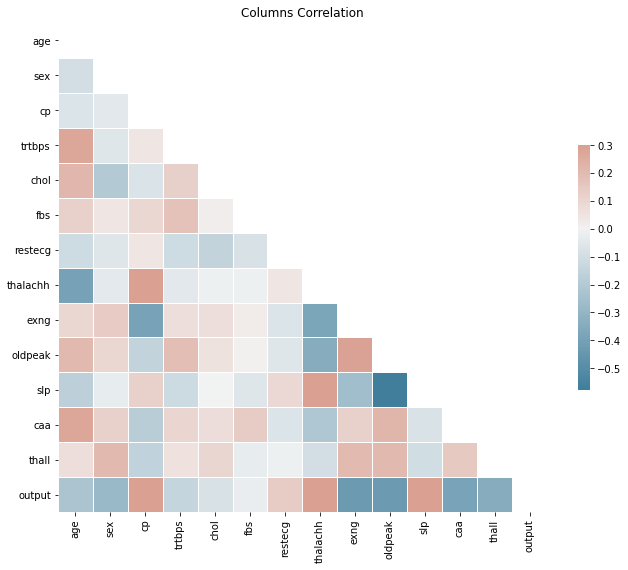
# check correlationcorr = heart_df.corr()# Generate a mask for the upper trianglemask = np.triu(np.ones_like(corr, dtype=bool))# Set up the matplotlib figuref, ax = plt.subplots(figsize=(11, 9))# Generate a custom diverging colormapcmap = sns.diverging_palette(230, 20, as_cmap=True)# Draw the heatmap with the mask and correct aspect ratiosns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0, square=True, linewidths=.5, cbar_kws={"shrink": .5}).set_title("Columns Correlation")
Text(0.5, 1.0, 'Columns Correlation')
# split data for trainingy = heart_df.output.to_numpy()X = heart_df.drop('output', axis=1).to_numpy()# scale X valuesscaler = StandardScaler()X = scaler.fit_transform(X)# split data while keeping output class distribution consistentX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)
# convert data to pytorch tensorsdef df_to_tensor(df): return torch.from_numpy(df).float()X_traint = df_to_tensor(X_train)y_traint = df_to_tensor(y_train)X_testt = df_to_tensor(X_test)y_testt = df_to_tensor(y_test)
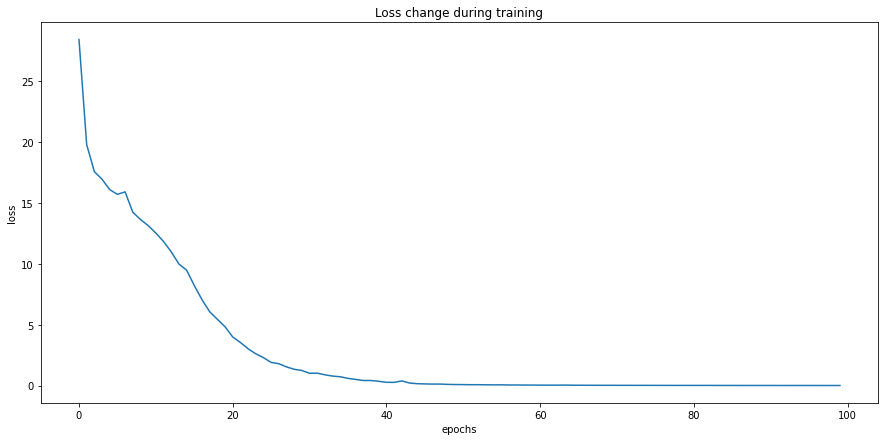
epochs = 100losses = []for i in range(epochs): epoch_loss = 0 for feat, target in train_dl: optim.zero_grad() out = model(feat) loss = loss_fn(out, target.unsqueeze(1)) epoch_loss += loss.item() loss.backward() optim.step() losses.append(epoch_loss) # print loss every 10 if i % 10 == 0: print(f"Epoch: {i}/{epochs}, Loss = {loss:.5f}")
Epoch: 0/100, Loss = 0.79641Epoch: 10/100, Loss = 0.03637Epoch: 20/100, Loss = 0.07704Epoch: 30/100, Loss = 0.02023Epoch: 40/100, Loss = 0.00084Epoch: 50/100, Loss = 0.00000Epoch: 60/100, Loss = 0.00001Epoch: 70/100, Loss = 0.00000Epoch: 80/100, Loss = 0.00018Epoch: 90/100, Loss = 0.00029
# plot lossesgraph = sns.lineplot(x=[x for x in range(0, epochs)], y=losses)graph.set(title="Loss change during training", xlabel='epochs', ylabel='loss')plt.show()
# evaluate the modely_pred_list = []model.eval()with torch.no_grad(): for X, y in test_dl: y_test_pred = model(X) y_pred_tag = torch.round(y_test_pred) y_pred_list.append(y_pred_tag)# convert predictions to a list of tensors with 1 dimentiony_pred_list = [a.squeeze() for a in y_pred_list]
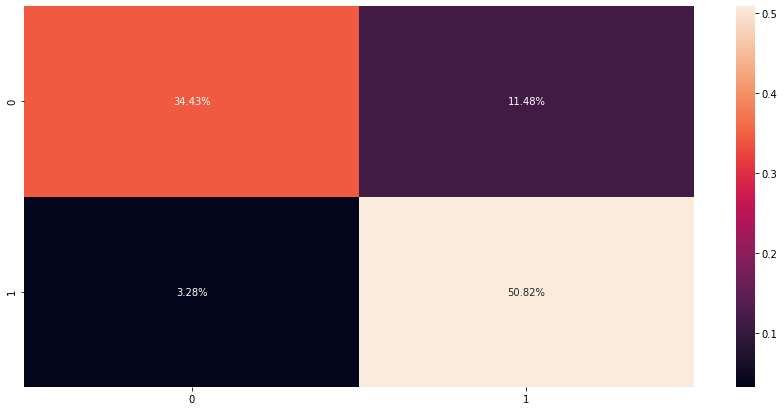
# check confusion matrix (hstack will merge all tensor lists into one list)cfm = confusion_matrix(y_test, torch.hstack(y_pred_list))sns.heatmap(cfm / np.sum(cfm), annot=True, fmt='.2%')